Mac 使用 Ollama 在本地部署 Gemma 4 大模型
前置条件
- 配备 Apple Silicon(M1/M2/M3/M4/M5)的 Mac mini
- 至少需要 16GB 统一内存用于 Gemma 4(默认 8B)
- macOS 已安装 Homebrew
- 网络(第一次下载模型需要,之后完全本地运行)
1. 检测环境
很多时候在本地运行模型失败,原因很简单:下了一个跑不动的模型。要么内存不够直接报错,要么勉强跑起来速度慢到没法用。
所以第一件事,先看一下系统环境是否满足要求。
1.1 使用 llmfit 检测
使用命令行终端工具 llmfit 扫一下当前电脑的硬件是否满足要求。
这个工具会自动检测电脑的 RAM、CPU、GPU,然后从几百个模型里筛出哪些能跑、哪些太大,按适配度排好。
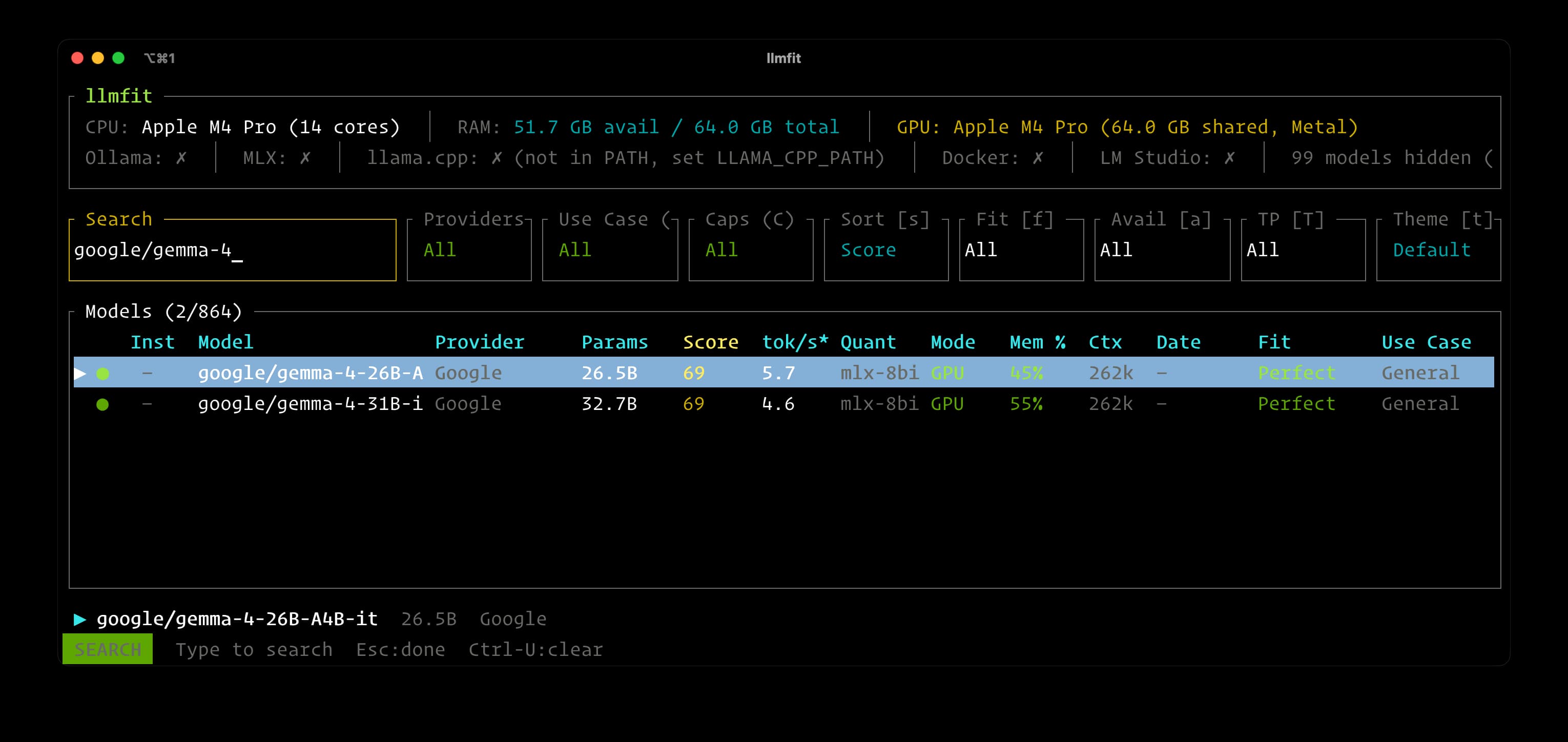
在终端中执行下面的命令:
brew install llmfit
安装完成后,执行命令:
llmfit
会进入一个交互界面,搜索感兴趣的模型名(google/gemma-4 或 qwen/qwen3.5),看一眼它标注的 Fit 一栏:Perfect 或 Good 都可以跑,Marginal 勉强,Too Tight 就别碰了。
1.2 使用在线地址检测
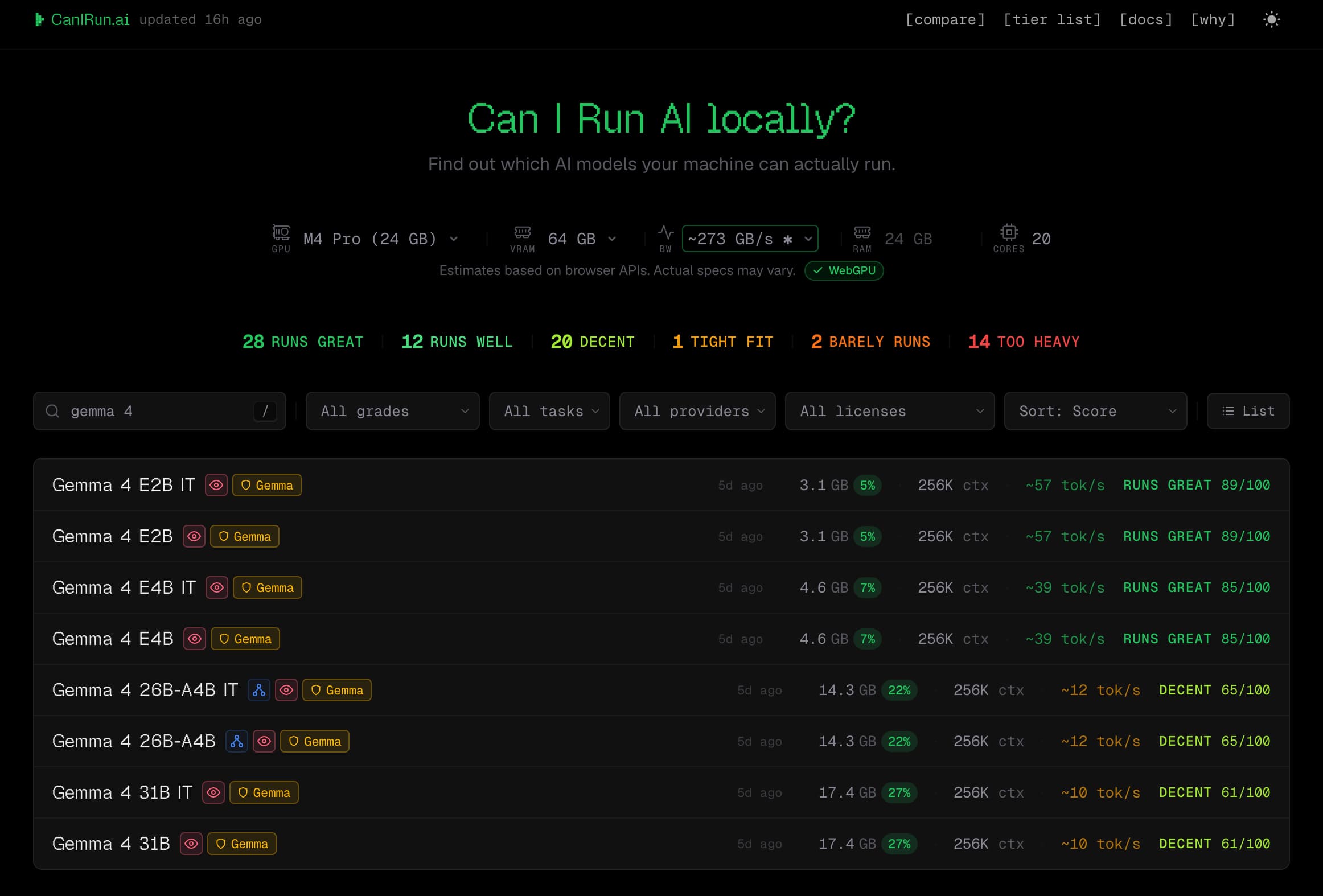
如果不想安装工具,也可以访问 canirun.ai 查看在线检测结果,这个网站会定期更新各种模型在不同硬件上的适配度测试结果。
选择你电脑的型号或显卡型号,搜索你想跑的模型,就能看到适配度评估结果。
2. 安装 Ollama
Ollama 是一个在本地运行大模型的工具,支持 Apple Silicon 的 Mac 设备。它提供了一个简单的命令行界面来管理和运行模型。
brew install --cask ollama-app
此操作将安装:
- Ollama.app 位于
/Applications/ - ollama 命令行工具位于
/opt/homebrew/bin/ollama
3. 启动 Ollama
open -a Ollama
Ollama 图标将出现在菜单栏。等待几秒钟让服务器初始化。
验证是否正在运行:
ollama list
4. 下载 Gemma 4 模型
目前推荐的两个选择是谷歌的 Gemma 4 和阿里的 Qwen3.5。
Gemma 4 是谷歌 DeepMind 在 2025 年发布的开源模型系列,最大亮点是原生支持多模态(文字+图片),上下文窗口达到 128K~256K,在同体量开源模型里综合表现靠前。
| 可用内存 | 模型版本 | 文件大小 |
|---|---|---|
| 16GB | gemma4:8b | 约 9.6GB |
| 32GB | gemma4:16b | 约 18GB(MoE架构) |
| 64GB | gemma4:31b | 约 20GB |
ollama pull gemma4
Ollama 会自动开始下载,进度条会显示在终端里。模型文件比较大,下载时间取决于你的网速,给它一点时间。
这将下载约 9.6GB。验证:
ollama list
# NAME ID SIZE MODIFIED
# gemma4:latest c6eb396dbd59 9.6 GB 3 days ago
5. 运行模型
ollama run gemma4:latest "你好,请问你是哪款模型?"
模型能正常回答,说明部署完成了。
检查是否使用 GPU 加速:
ollama ps
# NAME ID SIZE PROCESSOR CONTEXT UNTIL
# gemma4:latest c6eb396dbd59 14 GB 100% GPU 131072 4 minutes from now
6. 配置开机自启动
6.1. Ollama 应用 — 登录时启动
前往 系统设置 > 通用 > 登录项与扩展 并添加 Ollama。
6.2. 启动时自动预加载 Gemma 4
创建一个启动代理,在 Ollama 启动后将模型加载到内存中并保持其活跃状态:
cat << 'EOF' > ~/Library/LaunchAgents/com.ollama.preload-gemma4.plist
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>Label</key>
<string>com.ollama.preload-gemma4</string>
<key>ProgramArguments</key>
<array>
<string>/opt/homebrew/bin/ollama</string>
<string>run</string>
<string>gemma4:latest</string>
<string></string>
</array>
<key>RunAtLoad</key>
<true/>
<key>StartInterval</key>
<integer>300</integer>
<key>StandardOutPath</key>
<string>/tmp/ollama-preload.log</string>
<key>StandardErrorPath</key>
<string>/tmp/ollama-preload.log</string>
</dict>
</plist>
EOF
使用下面的命令加载代理
launchctl load ~/Library/LaunchAgents/com.ollama.preload-gemma4.plist
这样每 5 分钟向 ollama run 发送一个空提示,使模型保持在内存中活跃。
6.3. 永久保持模型加载状态
默认情况下,Ollama 在 5 分钟不活动后会卸载模型。
要保持模型一直加载:
launchctl setenv OLLAMA_KEEP_ALIVE "-1"
然后重启 Ollama 以使更改生效。
此环境变量是会话范围的。要跨重启持久化,请将
export OLLAMA_KEEP_ALIVE="-1" 添加到 ~/.zshrc 中。7. 接入现有工具
Ollama 还支持通过 API 接入现有的工具和应用,Ollama 运行后会在本地开放一个 API 接口,默认地址是 localhost:11434。比如:API访问,
Claude Code,Cherry Studio 等。
7.1 api访问
Ollama 在 http://localhost:11434 暴露了一个本地 API。使用它配合编程代理:
curl --location --request POST 'http://localhost:11434/v1/chat/completions' \
--header 'Accept: application/json' \
--header 'Content-Type: application/json' \
--header 'Host: localhost:11434' \
--header 'Connection: keep-alive' \
--data-raw '{
"model": "gemma4:latest",
"messages": [{"role": "user", "content": "Hello"}]
}'
7.2 Claude Code
Claude Code 是一个在线的代码编辑器,支持通过 Ollama API 接入本地模型。
只需在设置中配置 API 地址、Token和ApiKey,就可以直接在 Claude Code 中使用 Gemma 4 进行代码生成和编辑。
{
"env": {
"ANTHROPIC_BASE_URL": "http://localhost:11434",
"ANTHROPIC_AUTH_TOKEN": "ollama",
"ANTHROPIC_API_KEY": "",
"ANTHROPIC_MODEL": "gemma4:latest"
}
}
使用 Ollama 模型运行 Claude Code:
claude --model gemma4:latest
更多细节请参考官方文档:Ollama API Documentation。
实用命令
| 指令 | 描述 |
|---|---|
| ollama list | 列出已下载的模型 |
| ollama ps | 显示正在运行的模型及内存使用情况 |
| ollama run gemma4:latest | 交互式聊天 |
| ollama stop gemma4:latest | 从内存中卸载模型 |
| ollama pull gemma4:latest | 更新模型至最新版本 |
| ollama rm gemma4:latest | 删除模型 |
卸载/移除自动启动
# 移除自启动项
launchctl unload ~/Library/LaunchAgents/com.ollama.preload-gemma4.plist
rm ~/Library/LaunchAgents/com.ollama.preload-gemma4.plist
# 删除模型
ollama rm gemma4:latest
# 卸载 Ollama
brew uninstall --cask ollama-app